สืบเนื่องมาจากโพสนี้ครับ คือ ณ วันที่เขียนบทความนี้ เว็บ www.Nekopost.net (ตอนเข้าต้องมี www. ทุกครั้งไม่งั้น ajax เค้าพัง) ใช้วิธีป้องกันการขโมยรูปโดยใช้วิธีเอารูปจริงๆ ไปใส่ในภาพที่มีพื้นหลังสีขวา และภาพใหม่นั้นขนาดใหญ่กว่าภาพเดิม โดยใส่แบบสุ่มตำแหน่ง แล้วใช้ JS+CSS แสดงเฉพาะส่วนที่เป็นภาพหลักตรงๆ ผลคือหมาไฟ (Firefox) ผมมีโอกาศเพี้ยนเวลาที่มันกิน RAM ไปเยอะแล้วไปอ่านการ์ตูน (หรืออาจจะเป็นเพราะผมมีนิสัยกด END รัวๆเพื่อให้มันโหลดภาพทั้งหมดมาก่อนแล้วค่อยไล่อ่านรึเปล่า) ดังนั้นผมเลยเสนอวิธีไป (จริงๆวิธีที่ 1 คิดได้ตั้งแต่วันแรกที่เห็นมันทำแล้วแหละครับ แต่ไม่ได้ proof เป็น code สักที เพราะผมอยากพยายามหาวิธีที่กันการคัดลอก และดีกว่าที่เค้าใช้อยู่ โดยเชื่อว่าวิธีที่เค้าใช้ไม่ได้ดีที่สุด)
วิธีที่ 1 ใช้อีกภาพเป็น Key แล้วใช้ XOR กับต้นฉบับ
อันนี้เป็นวิธีแรกที่ผมมี Code อยู่ที่นี่ครับ หรือ Download พร้อม Sample Data ที่นี่ แนวคิดดังนี้
- สร้างภาพ Key ขึ้นมา เป็นภาพเล็กๆ สมมุติขนาด 64*64 px โดยแต่ละจุดสร้างจากการสุ่มสีขึ้นมารวมเป็นภาพมั่วๆ
- เอาแต่ละจุดของภาพต้นฉบับไป XOR กับภาพ Key ทีละสีเลย โดยใช้คุณสมบัติจาก
ถ้า a XOR b = c แล้ว c XOR b = a - ที่ Browser ใช้ Canvas ทำ Pixel Manipulation เพื่อทำการ XOR กลับมา
- แต่ถ้าสั่งแสดงที่ Canvas เลย ตัว Google Chrome มันเทพเกิน สามารถคลิกขวาที่ Canvas แล้ว Save As ได้ จึงต้องแปลงเป็น Data URI แล้วทำเป็น Background ให้ Div แทน
แต่เมื่อลองทำแล้ว เกิดปัญหาดังนี้
- Browser ต้องใหม่ระดับหนึ่ง (เพราะใช้ Canvas)
- มันกิน RAM มากๆ เวลาถอดรหัส อาจจะมากกว่าภาพใหญ่ของ Nekopost อีกต่างหาก
- ถ้าใช้กับ Mobile ที่ CPU ช้า อาจจะต้องรอนานกว่าภาพจะถอดรหัสเสร็จ (ระดับวินาที) และค่อนข้างกินแบตเตอรี่
- บน Tablet ผม (Samsung Galaxy Note 8) มีปัญหาว่า canvas เหมือนมันขี้เกียจทำบางจุด หรือประมวลผลผิดไม่รู้ทำให้มี Noise เป็นจุดสีๆเกิดขึ้นบนภาพ ทั้งๆที่บน PC ไม่เจอ
ดังนั้นแนวคิดนี้ผมเลยตกไป
วิธีที่ 2 สลับตำแหน่งของภาพ แนวคิดแบบตัวต่อจิ๊กซอว์
เป็นวิธีที่ 2 ที่ผมคิดมาแทนอันแรก ซึ่งตกไปในเรื่อง Performance และการใช้งานจริง วิธีนี้สามารถดู Code ได้ที่นี่ หรือ Download พร้อม Sample Data ที่นี่ แนวคิดดังนี้ครับ
- แบ่งภาพออกเป็น x คอลัมน์ y แถว โดย x ต้องหารความกว้างภาพลงตัว และ y ต้องหารความสูงภาพลงตัว (ถ้าไม่ลงตัวจะเกิดปัญหาภาพไม่ต่อกัน ดูไม่งามได้)
- สุ่มนำภาพแต่ละช่อง ไปวางมั่วๆบนภาพใหม่ แล้วสร้าง meta file บอกว่าเดิมนั้นแต่ละส่วนอยู่ตรงไหน
- เวลาแสดงก็อ่าน meta file มาสร้าง div ข้างในแทนแต่ละ block ให้แสดง background ของแต่ละช่องให้ถูกต้อง
ตัวอย่างภาพที่ผมทำ จะประมาณนี้
 Before Before |
 After After |
วิธีนี้หลังจากลองในเบื้องต้น พบว่าใช้ได้ OK เลย แต่มันมีปัญหานิดหน่อยใน Code ของผม คือมีส่วนที่ยุ่งเกี่ยวกับ DOM ที่ผมไม่ได้ Optimize อยู่ ดังนั้นถ้าแสดงภาพเยอะๆ จะทำให้เปิด Browser มาแล้วเหมือนค้าง หลังจากนั้นจะเร็วแล้วครับ
ผลจากวิธีที่ 2 สามารถลด RAM ได้มากกว่าวิธีที่ Nekopost ใช้ปัจจุบันเยอะมากครับ
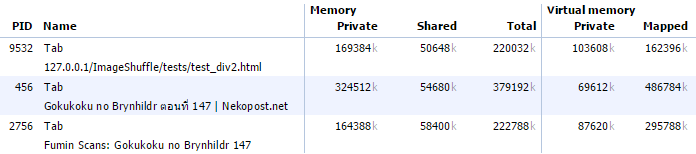
จากตาราง แสดงดังนี้
- PID 9532 เป็นวิธีจิ๊กซอว์ของผม
- PID 456 เป็นของ Nekopost
- PID 2756 เป็นภาพต้นฉบับจากเว็บคนแปลเลย (แต่ผมนั้นใช้ Adblock ทำการ block ส่วนของ social media กับ comment ทิ้ง เพื่อให้ขนาดใกล้เคียงนะครับ เหลือพวกภาพ Header กับโครงไว้)
ผลดังนี้ครับ
- จะเห็นวิธีผมกิน RAM ใกล้เคียงกับขนาดต้นฉบับค่อนข้างมากครับ (เทียบ 9532 กับ 2756) แต่ถ้าเทียบแค่ภาพจริงๆ ต้นฉบับน่าจะน้อยกว่าผม
- วิธีผมเมื่อเทียบกับ Nekopost ลด RAM เยอะมาก (จริงๆ Nekopost เพิ่ม RAM ที่ต้องใช้มากกว่า) จากเกือบ 400MB เหลือ 220MB (ทำไมภาพแค่ 23 ภาพมันแดก RAM เยอะจังวะ?)