This is my lab test for remove a moment locale from angular app. This article will show you how to reduce Angular bundled size by remove unused locale in moment.js without ng eject
WARNING: This is my first english article. I’m not good english but i think this should be share to other people.
Prepare a lab data
Just install Angular 7 and moment by this command.
ng new ng7-moment cd ng7-moment npm install --save moment
And edit `app.component.ts` to something like this
import { Component, OnInit } from '@angular/core';
import * as moment from 'moment';
@Component({
selector: 'app-root',
templateUrl: './app.component.html',
styleUrls: ['./app.component.css']
})
export class AppComponent implements OnInit {
time: string;
ngOnInit() {
this.time = moment().format('MMMM Do YYYY, h:mm:ss a');
}
}
And build a production bundle with stats json. by
npm run build -- --prod --stats-json
Next i see how many size of moment.js that include to bundle by
webpack-bundle-analyzer dist/ng7-moment/stats.json
And this i a result
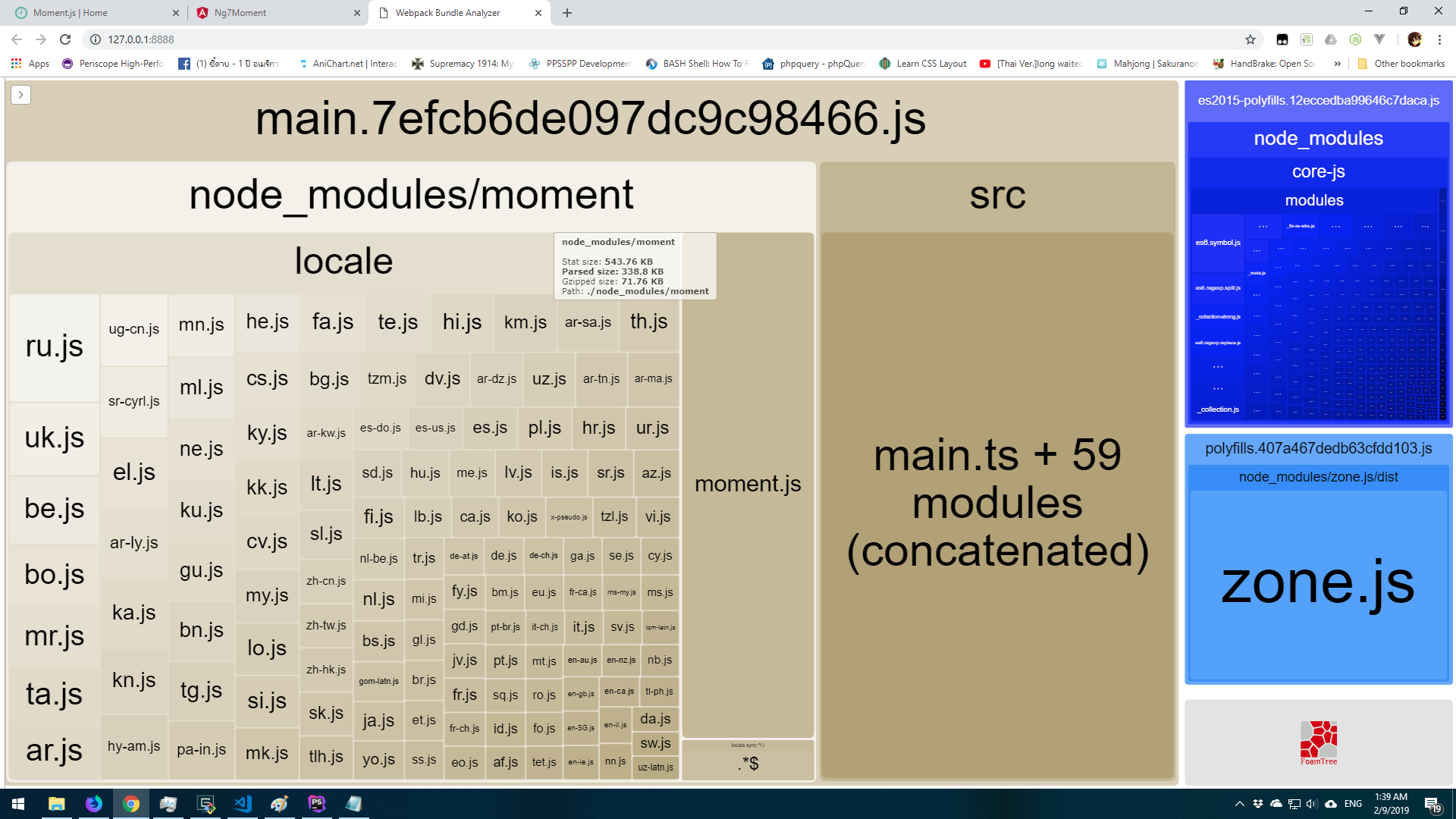
As you can see total size is around 300KB (Gzipped around 70KB).
First try: Import min edition
After I google for solution i found someone suggest that I can import moment.min.js. That file not include any locale data. So i change code to
import { Component, OnInit } from '@angular/core';
import * as moment from 'moment/min/moment.min.js';
@Component({
selector: 'app-root',
templateUrl: './app.component.html',
styleUrls: ['./app.component.css']
})
export class AppComponent implements OnInit {
time: string;
ngOnInit() {
this.time = moment().format('MMMM Do YYYY, h:mm:ss a');
}
}
The bundle size after changed is
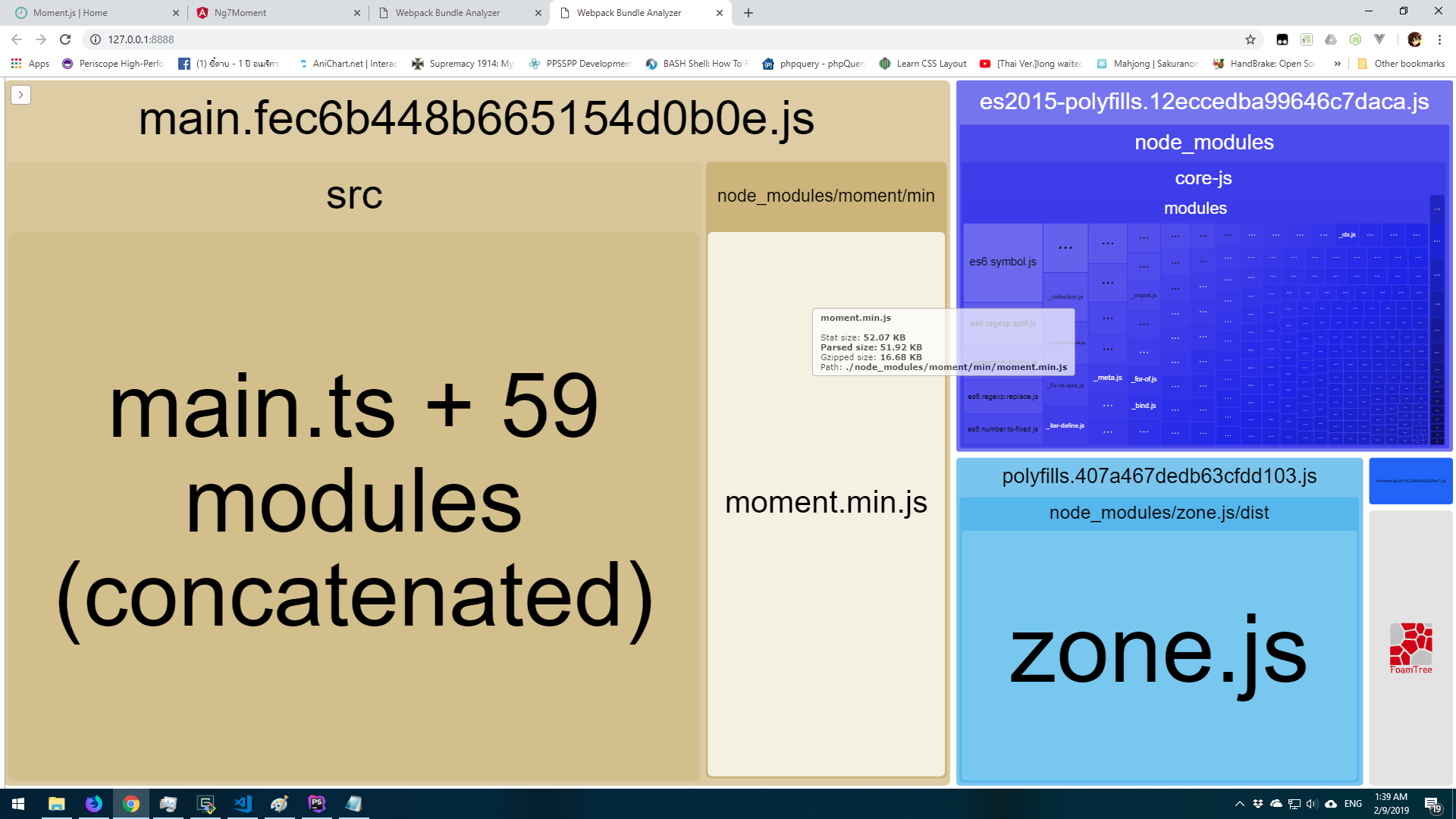
Now size is reduce to around 51KB (Gzipped around 16KB). WOW! At first time I think it works. But when I import a locale data like this code.
import { Component, OnInit } from '@angular/core';
import * as moment from 'moment/min/moment.min.js';
import 'moment/locale/th';
@Component({
selector: 'app-root',
templateUrl: './app.component.html',
styleUrls: ['./app.component.css']
})
export class AppComponent implements OnInit {
time: string;
ngOnInit() {
this.time = moment().format('MMMM Do YYYY, h:mm:ss a');
}
}
And see a bundled size.
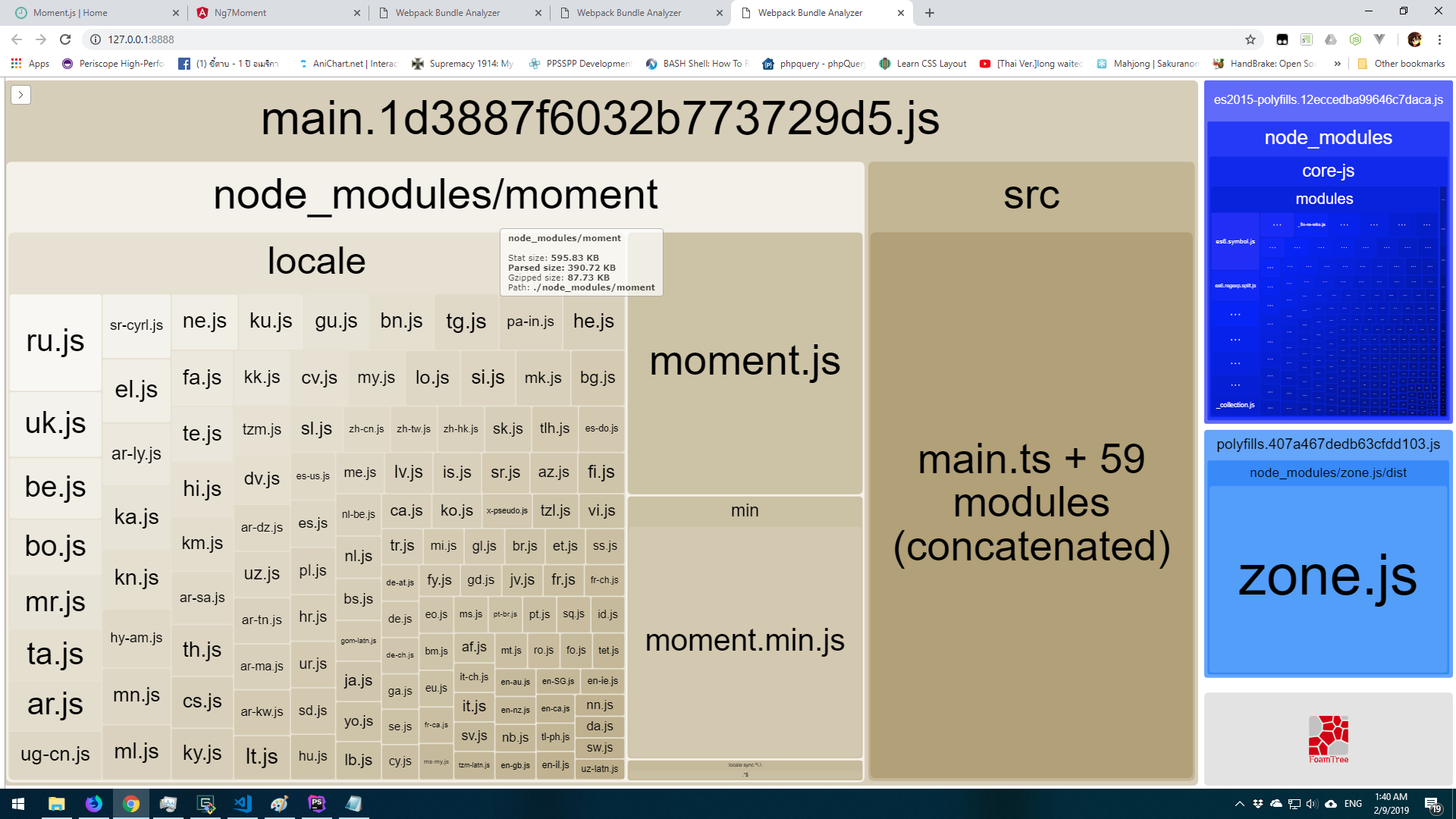 As you see we have 2 moment.js and full locale in bundled (one is full version and another one is min version). And if you import another library that use moment.js like chart.js the size will be like that too.
As you see we have 2 moment.js and full locale in bundled (one is full version and another one is min version). And if you import another library that use moment.js like chart.js the size will be like that too.
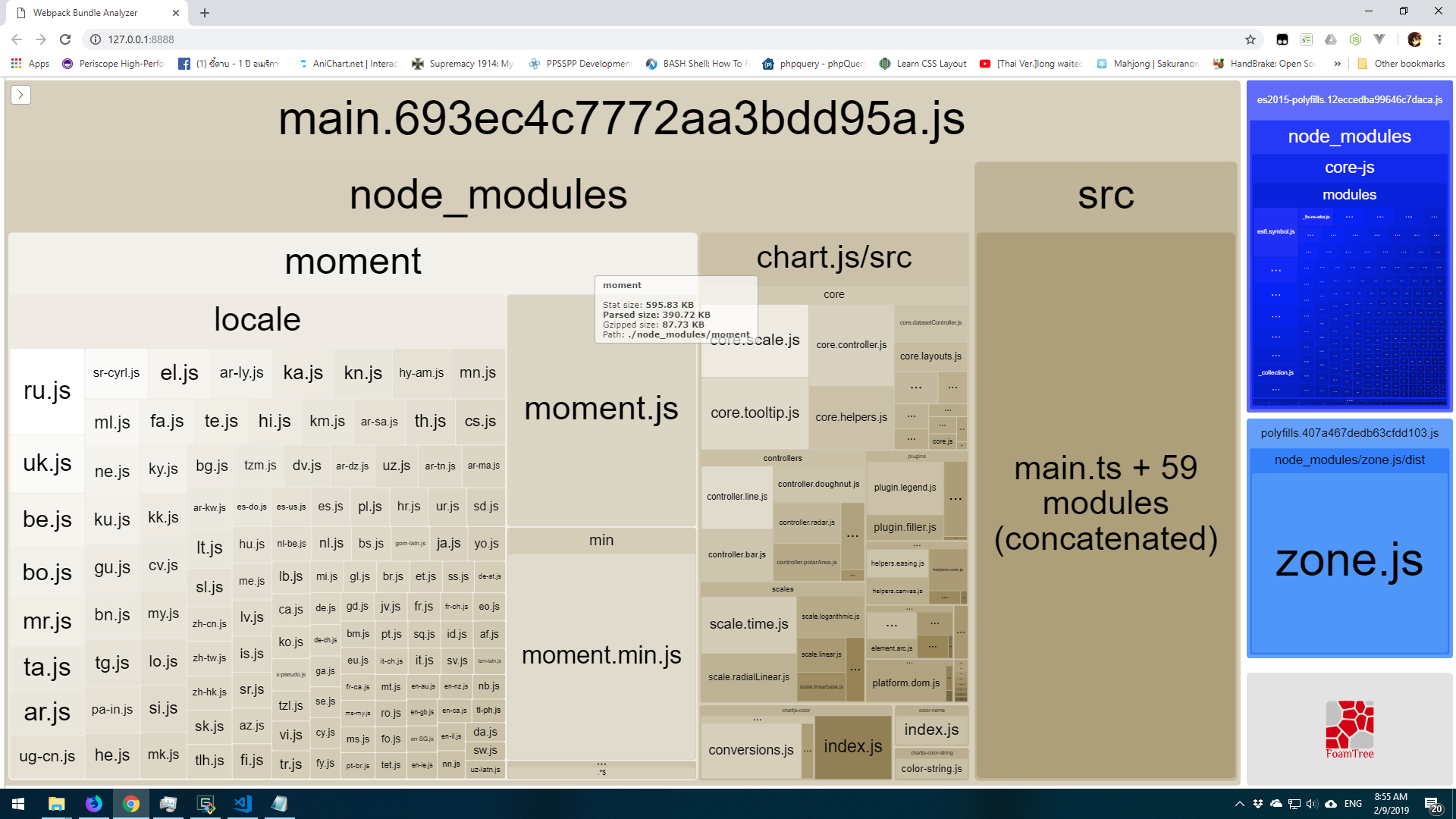
Second try: Use webpack plugins
I search in Google again. I see another solution to eject webpack config and add some plugin to remove locale. But for my personal reason i don’t want to eject angular config, So I will skip this solution for now.
Solution: Remove by Replace locale folders.
I found Angular has a feature that can replace environments file up to version that it build. I think I can use this folder to replace locale folder too. So let try
- Create a my locale folder and if you use any locale, copy it to this folder.
mkdir src/locale # If you want to use any locale copy it to your locale folder cp node_modules/moment/locale/th.js src/locale/
- Edit angular.json to replace default locale. file fileReplacements section and add this code like this.
"fileReplacements": [ { "replace": "src/environments/environment.ts", "with": "src/environments/environment.prod.ts" }, { "replace": "node_modules/moment/locale/", "with": "src/locale/" } ], - Build and see a results. (You will see a warning message like “node_modules/moment/locale/af.js” does not exist. But it OK don’t worry it)
The result is
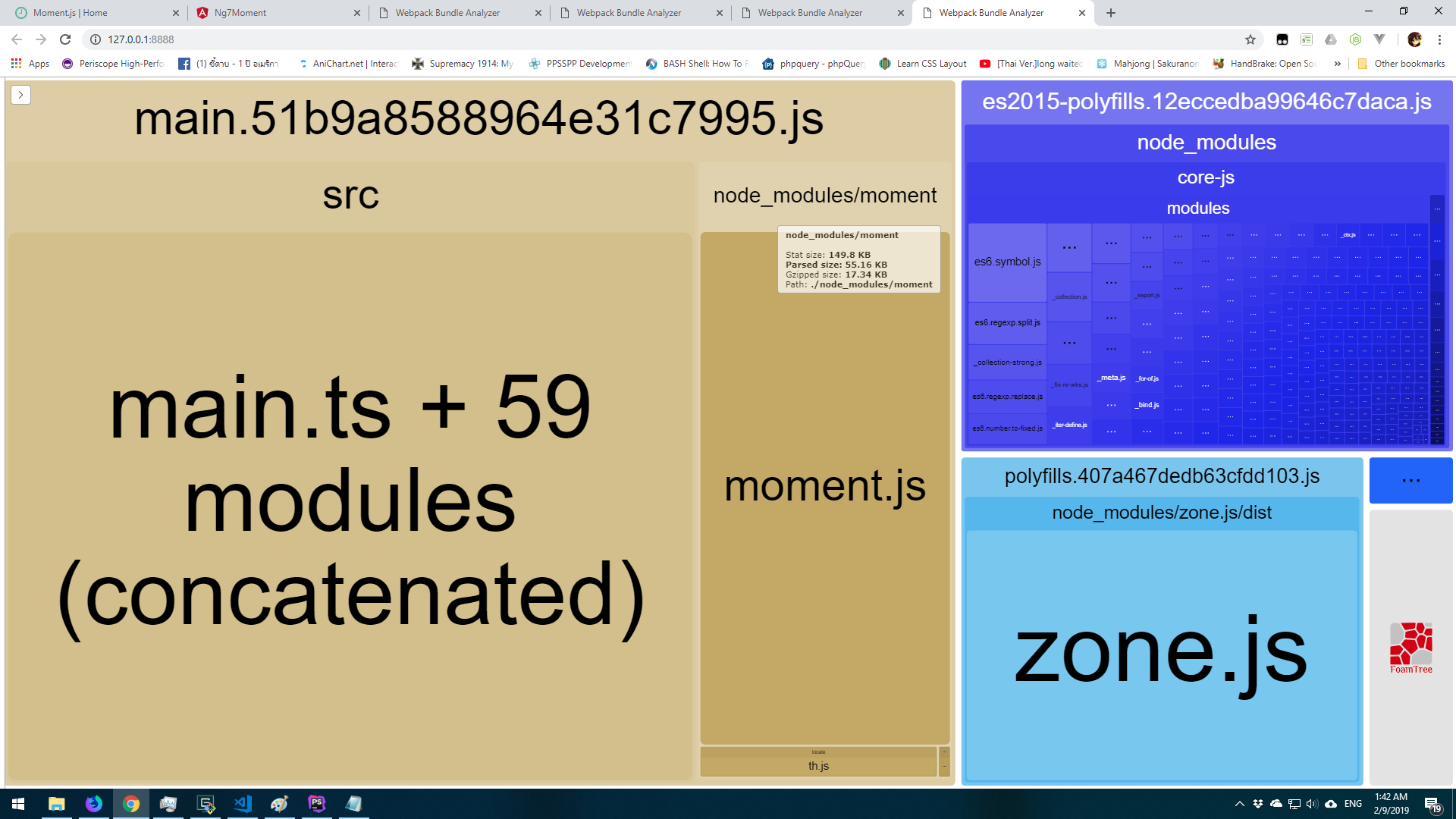 As you can see the size is around 55KB (Gzipped around 17KB) and no other locale except locale that in new locale folder. even if you import chart.js it still not include unused locale too. Like this
As you can see the size is around 55KB (Gzipped around 17KB) and no other locale except locale that in new locale folder. even if you import chart.js it still not include unused locale too. Like this
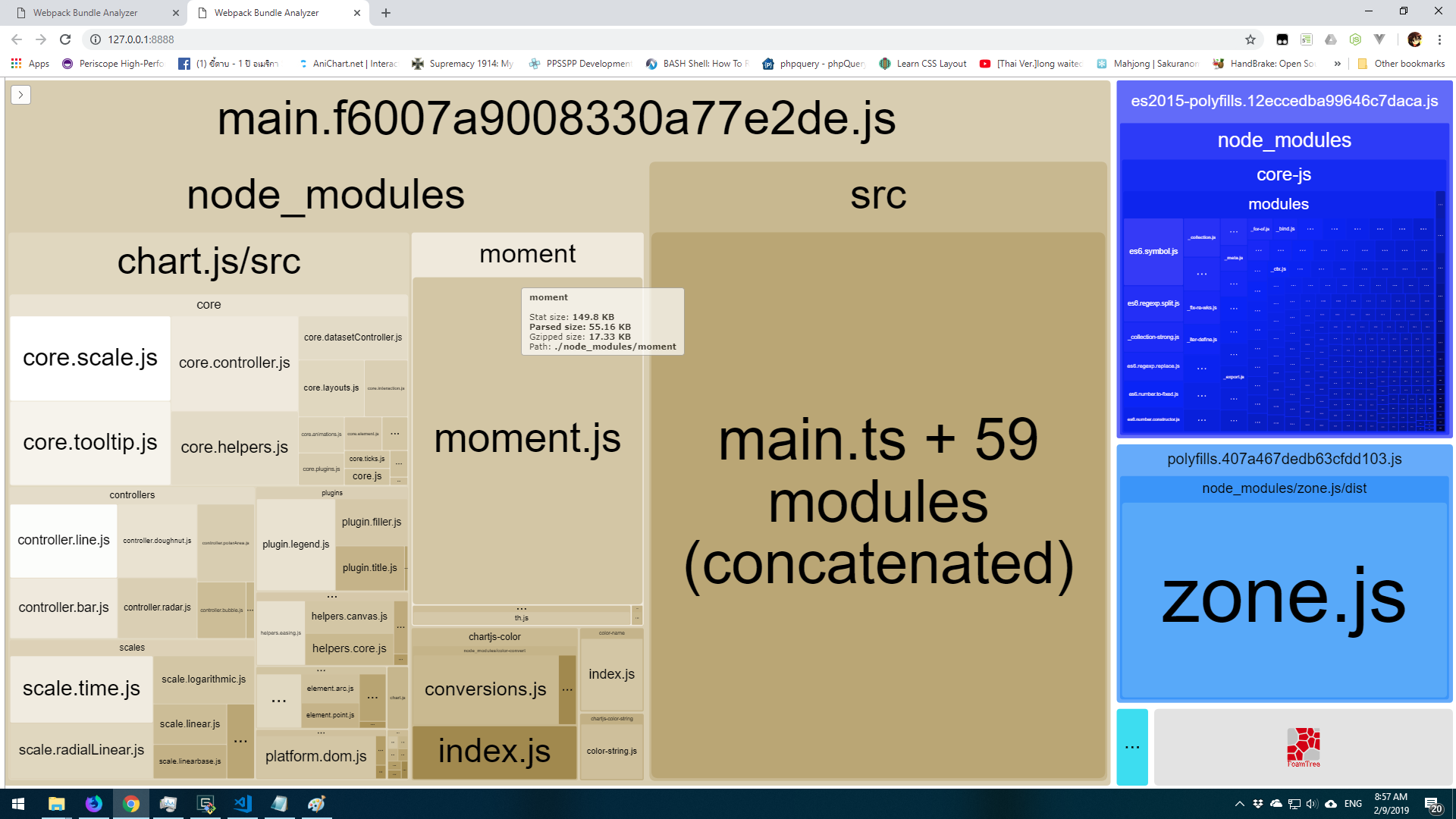
I hope this will be useful. Thanks for reading.